
最近和朋友同事在一起聊天,问起我正在做的项目-数据访问中间件,很多人都有一丝疑惑,这不是重复造轮子的事情么?业界里ORM框架有mybatis/hiberate,分库分表有sharding-jdbc/mycat等等,你们为什么还要新做一个框架?新做的框架有什么不一样?
对于这些问题,我希望通过本文能够帮助解决这些疑惑。本文主要介绍了数据库访问的技术架构,然后讨论了分片在不同架构层级的技术实现方案,对标业界各个数据库访问中间件,相互进行比较,分析各种架构的实现差别和优缺点。
目录
1. 什么是数据库分片
传统关系型数据库集中存储数据到单一节点,单表可以存储达数亿行的数据记录,通过主从备份作为灾备方案,保证数据的安全性,这基本可以覆盖大多数的应用场景。但是,随着互联网技术的发展,海量数据和高并发访问的应用场景日益增多,单表数据记录在突破一定阈值之后,其性能和可用性大幅下降。为了解决这个问题,将单一节点的数据拆分存储到多个数据库或表,即分库分表,使得关系型数据库能够存储的数据量阈值上限扩大1-2个数量级,从而满足业务需求。
数据库的分片拆分有两种方式,
- 按照业务划分的垂直拆分,将不同业务、不同模块的数据拆分为不同表。
- 按照容量平衡的水平拆分,将同一表的数据按照一定平衡策略,存储到不同数据库和表中。
前者的垂直拆分一般是一次性的,可以通过静态拆分实现(即停机拆分),而后者的水平拆分则需要技术框架的运行时刻支持。本文主要讨论水平拆分的技术架构实现,分析和对比相关框架和中间件。
讨论数据库分片的技术架构前,需要了解如下二个问题,
- 数据库访问的整个技术调用栈是怎样的?
- 在整个调用回路,哪里可以执行分片操作?如何实现?
2. Java数据库访问技术栈
先看看第一个问题,一个典型的Java应用,其数据库访问的技术调用栈如下图所示,
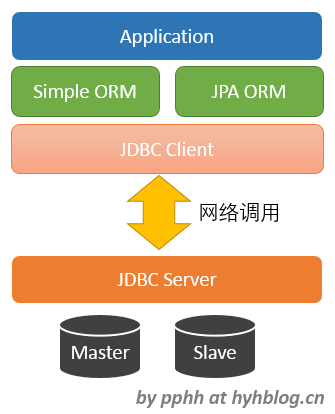
从上而下分别为,
- Application 应用程序
- ORM对象关系映射框架
- JDBC Client客户端
- JDBC Server服务端
- Database 物理数据库
这几个组件由上至下依次调用,相互之间进行输入输出。
下面一一介绍这几个技术组件的功能,为我们接下来讨论分片技术的实现和架构打下铺垫。
2.1 Application应用程序
在应用程序中有许多Java POJO对象,若希望将这些POJO对象存储到数据库中,首先要转换为ORM能够识别的、规范的Entity对象,也就是ORM框架中所定义的持久化对象(Persistent Entity),然后调用ORM提供的API对这些Entity对象进行增删改查操作。
2.2 ORM对象关系映射框架
ORM是Object Relation Mapping的简称,即对象关系映射。其定义了一个Java实体对象到数据库表的映射关系,使得我们对Java实体对象的各种增删改查操作可以进一步映射到对数据库表的SQL执行。业界中比较有名的Java ORM框架有Hibernate和MyBatis。
Java在JPA 2.2规范文档中针对ORM提供了语言上的实现规范。若ORM框架实现了JPA规范,则可称为JPA ORM,例如Hibernate、EclipseLink、OpenJPA、jOOQ(注1)。而有些ORM框架则实现了自定义的对象映射规范,比如MyBatis、Ctrip Dal等,在上图中被称之为Simple ORM。
ORM框架接受由上层应用程序所提供的Entity,并提供相应的增删改查API供应用程序调用,ORM将各种操作映射为Sql语句,并输出给下层的JDBC API执行。
2.3 JDBC Client
JDBC客户端主要实现了JDBC API规范文档中定义的接口,其主要包括如下几个接口组件,
- DataSource 数据库连接配置信息
- Connection 一个连接会话
- Statement 一个sql执行语句
- ResultSet 从数据库中获取的执行结果集
对于JDBC客户端来说,其接受ORM生成的sql语句,调用执行,然后返回结果集给ORM,然后ORM将结果集映射回规范化的Entity对象。
2.4 JDBC Server服务端
JDBC服务端一般指由物理数据库暴露给外部,实现了一定的通信协议,供外部组件通过网络远程调用访问后端的数据库。
业界中几个常见的数据库通信协议规范有,
| 协议 | 协议连接URL格式 |
|---|---|
| MySql | jdbc:mysql://host:port/datasource?serverTimezone=UTC&useSSL=false&useLocalSessionState=true |
| PostgreSQL | jdbc:postgresql://host:port/datasource |
| SqlServer | jdbc:sqlserver://host:port;DatabaseName=datasource |
| Oracle | jdbc:oracle:thin:@host:port:datasource |
各个物理数据库除了实现自己的通信协议,也可以采用已有流行的通信协议,比如分布式数据库的TiDB、AWS Aurora、OceanBase,以及数据访问中间件sharding-proxy、MyCat,都采用了兼容Mysql协议的接口服务。这使得用户和应用程序可以使用已有的Mysql客户端进行访问,方便用户和应用程序的接入。
作为JDBC服务端,其接受JDBC客户端远程调用时发送过来的Sql语句,执行后返回结果给JDBC客户端。
2.5 Database物理数据库
物理数据库本身的存储特性、容量性能、可扩展性,都对数据库技术分片技术的实现产生直接的影响。若物理数据库对分库分片提供原生支持,那么将大大简化分片技术的落地实现,比如阿里云的分布式关系型数据库产品DRDS。
3. 哪里分片、如何分片
在了解了数据库访问的技术调用栈之后,接下来的问题就是哪里分片、如何分片。
上文讲到分片是指将同一系列数据记录按照一定策略,存储到不同数据库和表中,使得数据的存储和读取达到最优解,这个策略就叫做分片策略。
常见的分片策略有,
- 简单的有按主键ID取模,平均分配记录到不同表中,平衡访问流量;
- 按地域分片,实现数据记录能够按最近IDC机房入库;
- 按时间分片,方便最新数据查询;
- 按数据关联度,比如和订单ID相关联的数据落入同一库,做到同库查询;
可以看到,分片策略依赖于分片字段的设计。
从分片技术实现的角度来说,分片字段的获取则是实现分片的第一步。在数据库访问的技术调用栈上,每层其实都可以获取到分片字段。下表描述了在各个技术调用栈层上,如何获取分片字段、如何实现分片策略,并列出了相应技术实现的分片框架、中间件或数据库,
| 数据库访问技术栈 | 如何获取分片字段 | 分片策略实现 | 技术实现 |
|---|---|---|---|
| ORM | 通过Entity解析 | Sql生成执行时分片 | MyBatis/Hibernate/Ctrip Dal |
| JDBC Client | 通过Sql解析 | 对Sql改写 | Sharding-JDBC |
| JDBC Server | 通过Sql解析 | 对Sql改写 | Sharding-Proxy, MyCat |
| 物理数据库 | 通过存储数据字段 | 原生支持分片策略 | 阿里云的DRDS |
上表中,分片字段的获取是区分不同分片架构实现的关键点之一,也影响着分片策略的技术实现。
4. Java数据库访问的分片技术架构实现
为了更加清晰地了解Java数据库访问的各个分片技术架构实现,下图以数据库访问技术调用栈层为基础,绘制了各个不同分片技术实现的架构,以便相互比较区分,
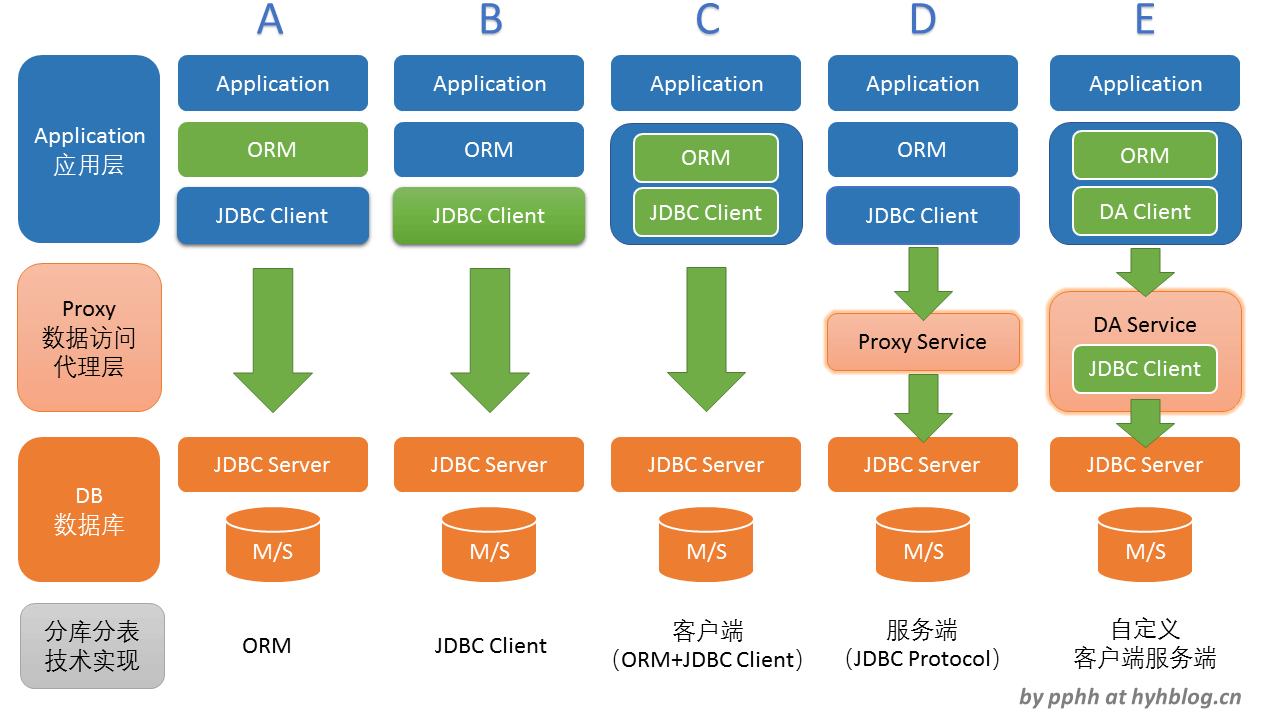
图中绘制了五种架构实现,分别为,
- ORM:在对象映射框架中提供分片技术实现。其主要优势是ORM握有持久化对象(Persistent Entity),可以非常容易地获取到分片字段,同时ORM框架为开发者提供各种扩展手段实现分片技术,比如DAO的继承实现自定义API,ORM拦截器等。开发者可以针对ORM框架编写扩展代码,以灵活的方式实现所需分片逻辑。其缺点在于绑定了特定ORM框架,分片逻辑对应用不透明。
- JDBC Client:对于JDBC客户端来说,其JDBC API接受上层传输过来的Sql语句,所以可以通过Sql解析,获取分片字段信息,然后对Sql进行改写。这个方式优点在于对应用和ORM框架透明,支持不同ORM框架,甚至更换ORM框架对分片逻辑无影响。缺点主要在于Sql解析,其对Sql语句有要求,不支持复杂的Sql语句,而且由于绑定JDBC Client,只支持单一开发语言。
- 客户端(ORM+JDBC Client):这里的客户端是指同时提供ORM和JDBC Client的框架,携程的DAL就是这样一个数据库访问客户端。其主要优点是,由于同时涵盖了ORM和JDBC Client两大技术栈层,因而技术空间将大为丰富,除了能够提供代码生成、拥有丰富API接口的数据库访问DAO、对应用程序透明的分库分表功能之外,最大的特点便是提供动态灵活的Sql构建器,Sql构建器+Entity+分库分表的技术结合,大大方便了开发者的使用。缺点是单一语言,由于包括了JDBC Client技术栈,其支持的数据库将受到限制,比如携程的DAL只支持MySql和SqlServer两种数据库。
- 服务端(JDBC Protocol):这个可以认为是第二种JDBC Client模式的服务化版本,在JDBC Server前部署一个中间代理服务,在代理服务里做sql解析和sql改写。其拥有JDBC Client模式几乎所有优缺点,不一样之处在于应用开发不再受到语言限制,可以支持多种应用开发语言,数据库连接数将得到高效复用。与此同时,这种服务化架构将方便实现sql的集中治理和限流监控功能,这也是服务化之后带来的一大好处。但是多一层网络跳转将对访问性能有一定的影响,服务的高可用性也需要特别留心设计。
- 自定义客户端和服务端:这个可以认为是上述第三种客户端模式的服务化版本。其拥有客户端模式的优缺点,也有服务化之后的优缺点。
还有一种是物理数据库原生支持分片策略,比如阿里的DRDS,这个架构非常简单,分片策略对应用、ORM、JDBC都透明,都由数据库中配置和实现,本文就不列出讨论。
5. 技术架构实现对比
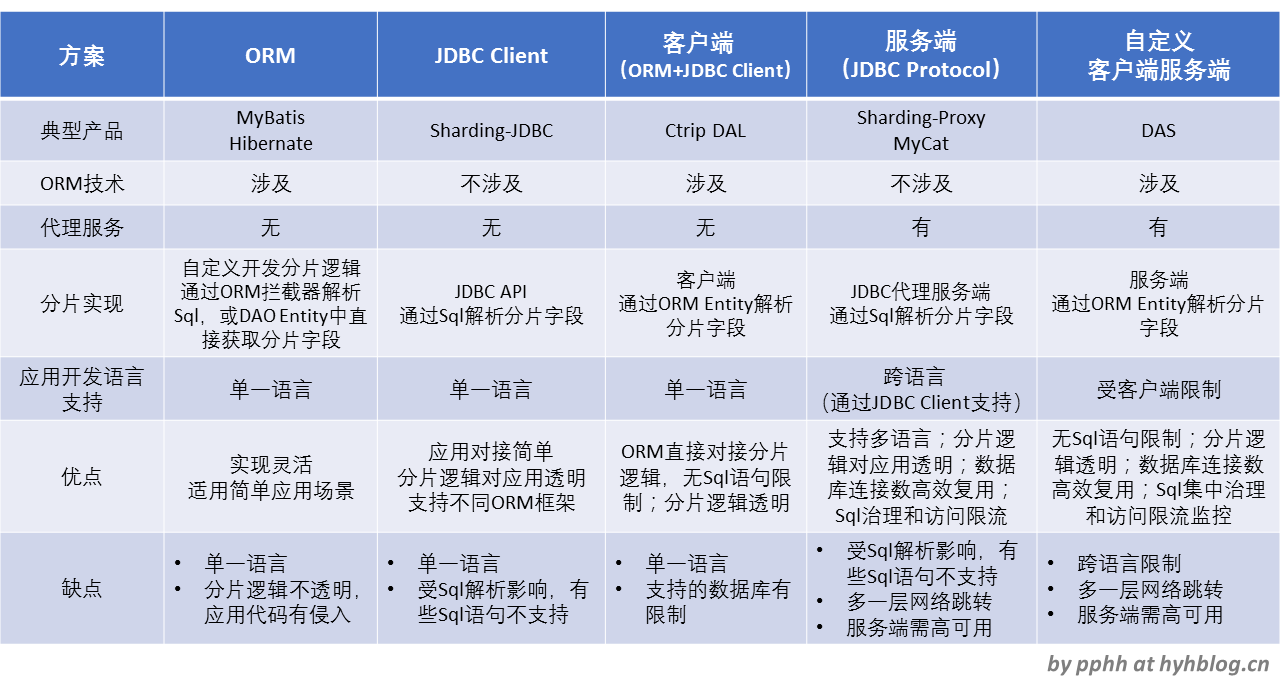
下表将各个分片技术方案的相关信息列出,作为对上述讨论的一个总结,
6. 是不是重复造轮子
区分是不是重复造轮子,一要判断架构是否有相似性,二要判断实现方式和提供的功能是否一样。即使是同一架构,同一实现功能,相互竞品之间也是有一定的性能特性区分。正所谓青出蓝而胜于蓝,长江后浪推前浪,在前人基础上,如何造出更好的轮子才是正道。
Hibernate、Sharding-JDBC、Ctrip DAL、MyCat四者分别以不同架构方式实现了数据库分片功能,通过上表可以知道,四者之间优缺点各有千秋,选择哪一种还是要取决于应用场景。
7. 分库分表的代价
我们在讨论分片的技术架构实现时,更需要了解的是分库分表所带来的成本代价。
分库分表操作不是一本万利的账,会带来新的风险和问题挑战,比如,
- 引入分库分表框架或中间件,其本身的技术掌握有一定成本,分库分表的配置管理和运行调试也是难点
- 数据记录插入容易,查询和Join变难
- 跨库的分布式事务,全局性约束失效(比如唯一主键)
- 自动化运维(灾备切换、数据库迁移等)实现
- 再扩容、更新分片算法
这些都是进行分库分表后面临的不小的成本代价。正确评估业务量和数据库能够承受的容量阈值,对症下药,是对分库分表的最佳建议。
以下是一些做分库分表前需要注意的考虑点,
- 若数据库的容量阈值足够满足业务量的数据记录需求,能不做分库分表则不做,避免不必要的成本代价。若不确定是否满足,可以先不做,待后续运营一段时间后再评估。
- 若业务量的数据记录需求超过数据库的容量阈值1-2个数量级,以审慎的态度考虑分库分片方案,并且对分库分表后的运营成本进行一定的考察。建议考虑下做定时数据备份清理工作,看能否把数据记录减少到数据库可支撑的范围之内,避免分库分表。只有在数据量超过容量阈值,数据库读写速度满足不了业务需求时,分库分片才是一个可选解决方案。
- 若业务量的数据记录需求超过数据库的容量阈值3-N个数量级,这个时候,数据量也超过了分库分片所能承受的应用场景。有这么大数量级的业务数据,分布式关系数据库是一个方向,比如谷歌的Spanner,亚马逊云的Aurora,PingCAP的TiDB、阿里的OceanBase,其可以支撑的数据量都可达万亿行以上。
8. 参考资料
- 注1:jOOQ可以自动生成JPA实体代码,并通过JPA native query API来实现对实体的操作,一个使用方法如下所示,
EntityManager.createNativeQuery(org.jooq.Query.getSQL(), resultSetMapping)
- JPA 2.2规范文档
- JDBC 4.3 规范文档
- PingCAP的TiDB:https://www.pingcap.com/docs-cn/
- Sharding-Sphere:http://shardingsphere.io/
- Ctrip Dal开源项目:https://github.com/ctripcorp/dal
- 阿里云的分布式关系型数据库产品:DRDS