1. 介绍
微服务架构中,分布式追踪(distributed tracing)是一个关键的基础功能,通过分布式追踪技术,我们可以深入分析一次请求调用所执行的路径、性能消耗,帮助定位性能瓶颈点,透明化服务之间上下游网络调用关系,帮助优化服务层次依赖问题。
Dubbo RPC是业界常用的一个开源RPC框架,而Jaeger也是业界流行的一个开源分布式追踪组件,本文将介绍如何把Dubbo RPC调用链接入Jaeger追踪,文末将结合分布式追踪技术,对常见的问题案例进行分析和给出优化方案。
2. 追踪数据模型和dubbo埋点实现原理
Jaeger的追踪实现遵循了OpenTracing语义规范,其数据模型是一个trace包含多个span构成的有向无环图,如下是一个典型的trace样例,
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C is a `ChildOf` Span A)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G `FollowsFrom` Span F)
更多OpenTracing术语的定义和详细介绍请见这里,本文将不赘述。
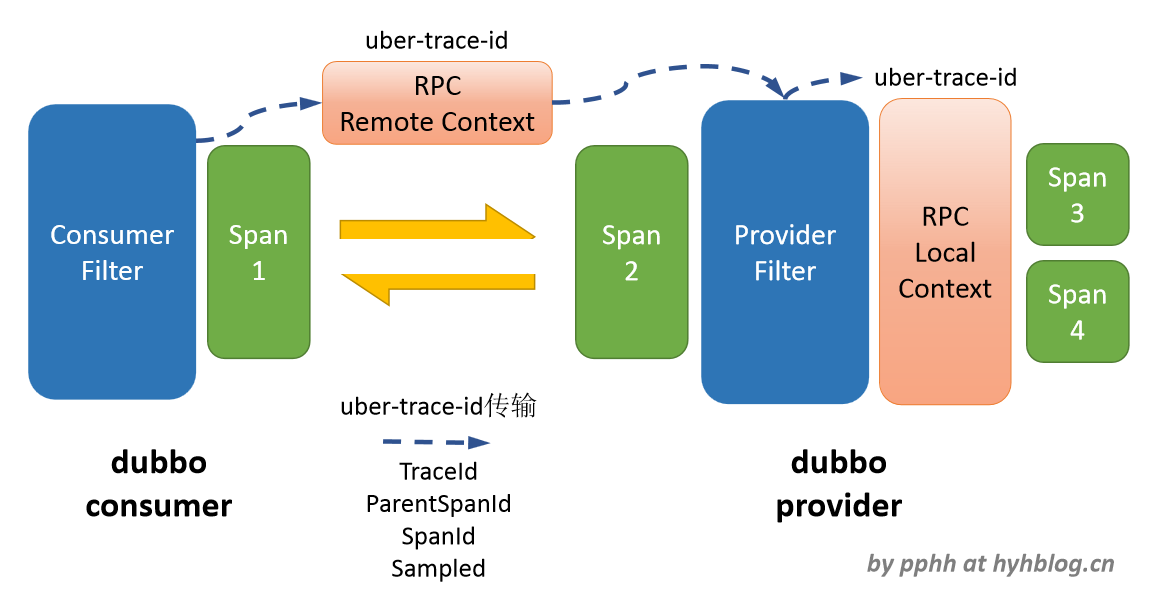
若要将Dubbo RPC接入Jaeger追踪,从consumer到provider一次调用为最基本的追踪单元,整个dubbo的调用追踪可以视为该基本单元的规模扩展,因此该基本单元的追踪埋点实现是Dubbo RPC接入Jaeger追踪的核心。
下图为对这个基本追踪单元的埋点实现描述,
3. 代码实现
下面为简化版的RpcConsumerFilter实现代码,
@Activate(group = {Constants.CONSUMER})
public class RpcConsumerFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
// 获取context并创建span
RpcContext rpcContext = RpcContext.getContext();
Span span = DubboTraceUtil.extractTraceFromLocalCtx(rpcContext);
Result result = null;
try {
// 将span context加载到dubbo rpc remote context中
DubboTraceUtil.attachTraceToRemoteCtx(span, rpcContext);
// 执行dubbo rpc调用
result = invoker.invoke(invocation);
} catch (RpcException rpcException) {
span.setTag("error", "1");
throw rpcException;
} finally {
span.finish();
}
return result;
}
}
下面为简化版的RpcProviderFilter实现代码,
@Activate(group = {Constants.PROVIDER})
public class RpcProviderFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
// 获取context并创建span
RpcContext rpcContext = RpcContext.getContext();
Span span = DubboTraceUtil.extractTraceFromRemoteCtx(rpcContext);
Result result = null;
try {
// 将span context加载到dubbo rpc local context中
DubboTraceUtil.attachTraceToLocalCtx(span, rpcContext);
// 执行dubbo rpc调用
result = invoker.invoke(invocation);
} catch (RpcException rpcException) {
span.setTag("error", "1");
throw rpcException;
} finally {
span.finish();
}
return result;
}
完整的代码演示样例请见这里。
4. 埋点上报的span数据格式
| 数据字段 | 字段类型 | 是否必要字段 | 说明 |
|---|---|---|---|
| traceId | 字符串 | Y | 当前span所属的一次调用跟踪ID |
| spanID | 字符串 | Y | 当前span的ID |
| parentSpanID | 字符串 | Y | 父spanID,串联上下游span |
| startTime | 长整型 | Y | 当前span的开始时间 |
| duration | 长整型 | Y | 当前span的时长 |
| tags.span.kind | 字符串 | Y | 当前调用方类型:server/client |
| tags.sampler.type | 字符串 | 抽样器类型 | |
| tags.sampler.param | 字符串 | 抽样比例,取值范围:0-1 | |
| tags.peer.hostname | 字符串 | 对调方的主机名/IP | |
| tags.peer.port | 短整型 | 对调方的端口 | |
| operationName | 字符串 | Y | dubbo接口名 |
| tags.arguments | 字符串 | Y | dubbo接口调用的参数 |
| tags.error | 字符串 | Y* | 当前dubbo调用出现异常或错误,值为“1”,注:该字段只有在有错误异常情况下为必要字段 |
| tags.error.code | 字符串 | dubbo的异常码 | |
| tags.error.message | 字符串 | dubbo的异常消息 |
如下分别为来自dubbo consumer/provider的span上报数据样例,
// 消费方span
{
"traceID": "5eb2e61e850be731",
"spanID": "5eb2e61e850be731",
"parentSpanID": "0",
"startTime": 1592835612981000,
"duration": 9781,
"operationName": "com.pphh.demo.common.service.SimpleService:save",
"tags.span.kind": "client",
"tags.sampler.type": "probabilistic",
"tags.peer.service": "com.pphh.demo.common.service.SimpleService",
"tags.sampler.param": "1.0",
"tags.arguments": "[{\"userName\":\"michael\"}]",
"tags.peer.hostname": "192.168.1.105",
"tags.peer.port": "29001"
}
// 提供方span
{
"traceID": "5eb2e61e850be731",
"spanID": "c7aaec2ab0a20823",
"parentSpanID": "5eb2e61e850be731",
"startTime": 1592835612986000,
"duration": 1880,
"operationName": "com.pphh.demo.common.service.SimpleService:save",
"tags.span.kind": "server",
"tags.peer.service": "com.pphh.demo.common.service.SimpleService",
"tags.arguments": "[{\"userName\":\"michael\"}]",
"tags.peer.hostname": "192.168.1.105",
"tags.peer.port": "49707"
}
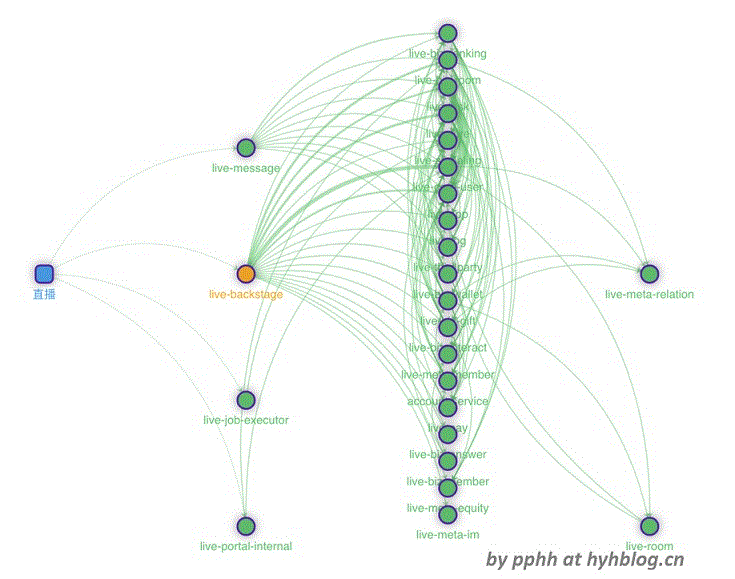
5. Dubbo RPC分布式追踪大图
将所有dubbo rpc调用的上报span数据按应用聚合,可以看到整个Dubbo RPC分布式追踪大图,
6. 通过分布式追踪发现的常见问题案例
6.1 应用服务依赖:多次重复rpc调用/上下依赖倒置
通过分布式追踪大图可以清晰地看到各个应用的调用关系,应避免不必要的重复rpc调用,禁止底层应用调用上层应用。
6.2 大流量调用
分布式追踪大图中,调用线条的粗细描述了各个调用关系的流量大小,
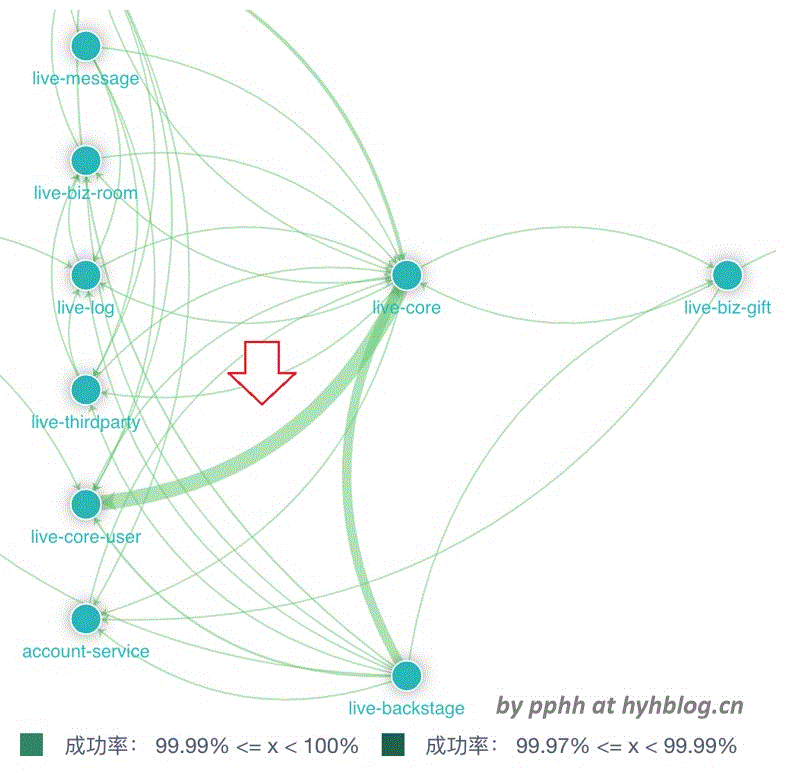
对于大流量调用,需要评估其流量的合理性,减少不必要的RPC调用开销,可以考虑从如下几个方面进行优化,
1. 循环多次调用转为单次批量调用。
2. 若是读操作,接受数据的时延,可以考虑使用local cache,在指定的N秒内,直接读取local cache。
3. 应用服务拆分,隔离因大流量调用而产生的CPU/内存/网络等资源竞争。
6.3 性能问题 - 重复调用转为单次批量调用
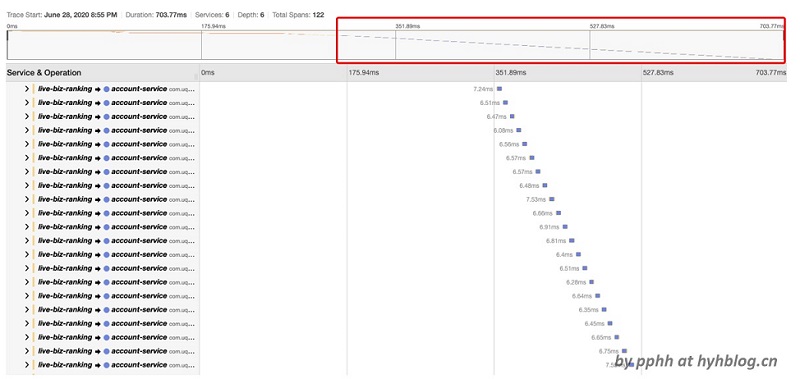
该问题典型场景为在一个循环中重复执行RPC调用,其调用性能取决于循环的次数,比如获取100个用户信息,循环100次获取用户信息,这个问题最好的办法是将循环调用转为单次批量调用。
下图为一个重复调用的追踪图,
6.4 异常调用定位 - 非法参数
对于异常调用,可以查看异常信息,并结合调用的参数,定位问题,比如用户名非法的异常,可以查看调用参数,用户名是否包含非法字符。
6.5 网络抖动
这种问题常见的现象是,整个调用链中,上游span耗时非常长,下游span耗时非常短,见下图,
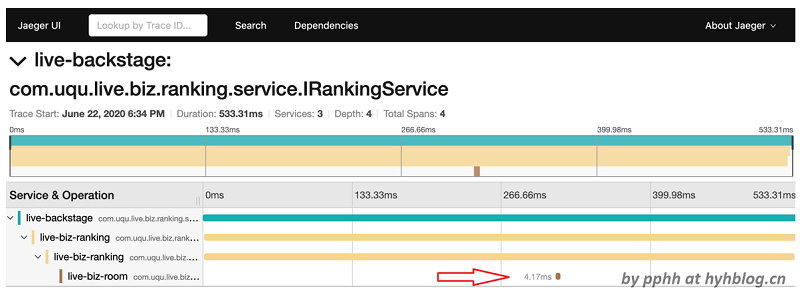
可以看到,上下游都被执行,但是上下游衔接耗时很长,其问题的原因主要出现在上下游衔接。上图中的问题后来定位到网络抖动导致。