
WxJava是一个目前应用广泛的微信SDK工具开发包,本文记录一个WxJava获取微信AccessToken失败出现acquire timeouted的问题。
1. 故障现象
最近产线出现了一个严重的技术故障问题,用户无法登录长达1个多小时,通过查看日志发现和WxJava相关,在故障期间内,WxJava一直无法正常获取微信Access Token,报acquire timeouted的错误,见下图。

期间尝试重启两次,在19:20第一次重启应用后问题有所减弱,但是过了5分钟又重新大量发生,直到第二次重启应用后问题消失。
2. 问题定位
通过查看错误日志的堆栈信息,
java.lang.RuntimeException: acquire timeouted
at cn.binarywang.wx.miniapp.config.impl.WxMaRedisConfigImpl$DistributedLock.lock(WxMaRedisConfigImpl.java:332)
at cn.binarywang.wx.miniapp.api.impl.WxMaServiceImpl.getAccessToken(WxMaServiceImpl.java:110)
at cn.binarywang.wx.miniapp.api.impl.WxMaServiceImpl.executeInternal(WxMaServiceImpl.java:249)
at cn.binarywang.wx.miniapp.api.impl.WxMaServiceImpl.execute(WxMaServiceImpl.java:215)
at cn.binarywang.wx.miniapp.api.impl.WxMaServiceImpl.get(WxMaServiceImpl.java:199)
at cn.binarywang.wx.miniapp.api.impl.WxMaServiceImpl.jsCode2SessionInfo(WxMaServiceImpl.java:178)
at cn.binarywang.wx.miniapp.api.impl.WxMaUserServiceImpl.getSessionInfo(WxMaUserServiceImpl.java:28)
可以看到和WxJava通过分布式锁获取token有关,产线用的WxJava代码版本是3.6.0,之前已经稳定运行了一年多。
下载相应版本WxJava代码,找到报错的代码行,
// 类文件 - cn.binarywang.wx.miniapp.api.impl.WxMaServiceImpl
public class WxMaServiceImpl implements WxMaService {
public String getAccessToken(boolean forceRefresh) throws WxErrorException {
if (!this.getWxMaConfig().isAccessTokenExpired() && !forceRefresh) {
return this.getWxMaConfig().getAccessToken();
}
Lock lock = this.getWxMaConfig().getAccessTokenLock();
lock.lock(); // <-- 问题发生代码行 WxMaServiceImpl.java:110
try {
String url = String.format(WxMaService.GET_ACCESS_TOKEN_URL, this.getWxMaConfig().getAppid(),
this.getWxMaConfig().getSecret());
try {
HttpGet httpGet = new HttpGet(url);
if (this.getRequestHttpProxy() != null) {
RequestConfig config = RequestConfig.custom().setProxy(this.getRequestHttpProxy()).build();
httpGet.setConfig(config);
}
try (CloseableHttpResponse response = getRequestHttpClient().execute(httpGet)) {
String resultContent = new BasicResponseHandler().handleResponse(response);
WxError error = WxError.fromJson(resultContent, WxType.MiniApp);
if (error.getErrorCode() != 0) {
throw new WxErrorException(error);
}
WxAccessToken accessToken = WxAccessToken.fromJson(resultContent);
this.getWxMaConfig().updateAccessToken(accessToken.getAccessToken(), accessToken.getExpiresIn());
return this.getWxMaConfig().getAccessToken();
} finally {
httpGet.releaseConnection();
}
} catch (IOException e) {
throw new RuntimeException(e);
}
} finally {
lock.unlock();
}
}
}
// 类文件 - cn.binarywang.wx.miniapp.config.impl.WxMaRedisConfigImpl$DistributedLock
public class WxMaRedisConfigImpl implements WxMaConfig {
private class DistributedLock implements Lock {
private JedisLock lock;
private DistributedLock(String key) {
this.lock = new JedisLock(getRedisKey(key));
}
@Override
public void lock() {
try (Jedis jedis = jedisPool.getResource()) {
if (!lock.acquire(jedis)) {
throw new RuntimeException("acquire timeouted"); // <-- 问题发生代码行 WxMaRedisConfigImpl.java:332
}
} catch (InterruptedException e) {
throw new RuntimeException("lock failed", e);
}
}
// ...
}
}
上面的代码主要是通过redis分布式锁,使得只有一个进程中的一个线程执行token获取并存储到redis,梳理getAccessToken()方法的执行路径,可以发现其大概经历的步骤如下,

若仔细研读这个流程图,可以发现其中有很多相互抢占竞争资源的问题,其中有竞争的资源有3处,
- DistributedLock.lock():分布式锁,多个进程/线程抢占这个锁,只有获取到此锁的线程才能执行锁更新操作。
- jedisPool.getResource():单进程中多个线程竞争从连接池获取redis连接。
- JedisLock.acquire()和JedisLock.release():两个方法被synchronized修饰,这个是一个比较隐蔽的同步琐,被单进程中的多个线程所竞争抢占。
2.1 问题一:在jedisPool.getResource()时等待超时
如下图所示,

整个获取token过程需要多次获取jedisPool.getResource(),特别是获取到分布式锁的线程,即使通过http请求获取到了微信token之后,并不一定能够顺利地将token写入redis,因为写入时还需要再获取一次redis连接,若获取redis连接失败,则可能刷新token失败。
2.2 问题二:多次频繁刷新token
如下图所示,
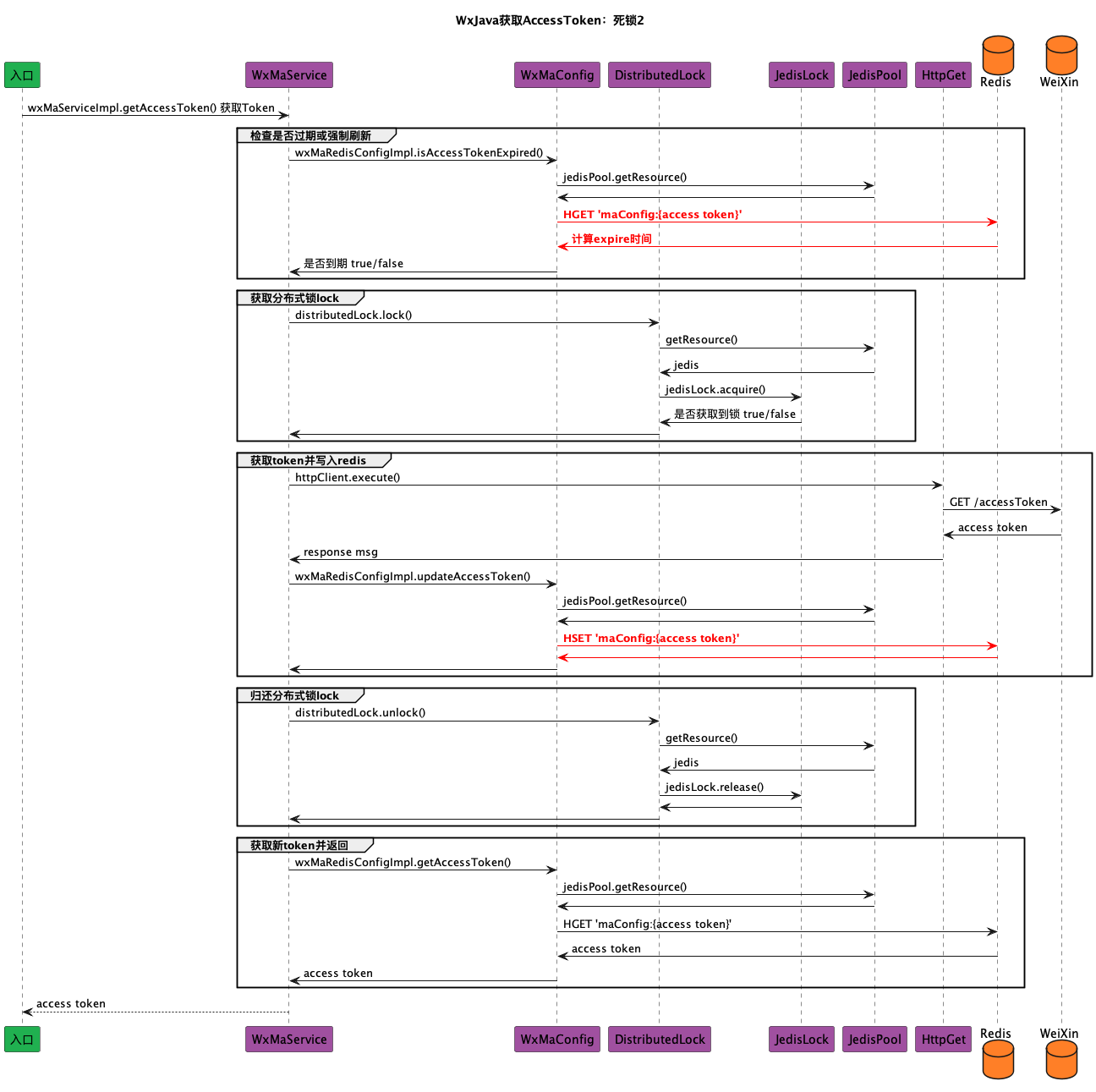
在多个并发情况下,受到分布式锁的影响,当拥有锁的一个线程在更新token的时候,多个线程会被阻塞在distributedLock.lock(),但第一个拥有分布式锁的线程更新完token,所有其它阻塞的线程会继续执行后续的token刷新操作,进而导致频繁刷新token,在最差情况下,可能会导致一直无序地循环刷新token。
2.3 问题三:无法通过JedisLock.release()释放分布式锁
如下图所示,

当拥有分布式锁的一个线程结束更新token时,需要通过JedisLock.release()释放分布式锁,但是注意JedisLock.acquire()和JedisLock.release()两个方法被synchronized修饰,它们两个需要竞争抢占同一个JedisLock对象上的同步锁,很有可能的情况下,由于其它线程不停的acquire(),导致当前拥有分布式锁的线程永久无法得到释放。
3. 解决方案
可以看到3.6.0版本上的WxMaServiceImpl.getAccessToken()很多问题,根本原因就是在代码实现中几个竞争资源被来回穿插抢占,如何将锁资源的竞争关系解放,是解决关键。
如下是一个解决方案的示例代码,
// 类文件 - cn.binarywang.wx.miniapp.api.impl.WxMaServiceImpl
private String getAccessToken(boolean forceRefresh) throws WxErrorException{
if (!this.getWxMaConfig().isAccessTokenExpired() && !forceRefresh) {
return this.getWxMaConfig().getAccessToken();
}
// 若是redis分布式锁实现,则走新方法更新token
if (this.getWxMaConfig() instanceof WxMaRedisConfigImpl){
return getAccessTokenV2((WxMaRedisConfigImpl) this.getWxMaConfig(), forceRefresh);
}
// 略...
}
/**
* 更新redis中的token并返回
* @param redisConfig
* @param forceRefresh
* @return
*/
private String getAccessTokenV2(WxMaRedisConfigImpl redisConfig, boolean forceRefresh) throws WxErrorException{
// 处理1:获取分布式锁的当前线程,后续都将使用当前jedis连接完成后续操作
Jedis jedis = redisConfig.getJedis();
try{
DistributedLock lock = redisConfig.AccessTokenLock();
lock.lock(jedis);
log.info("当前线程获取到redis分布式锁");
try {
// 处理2:二次判断token是否有效
if (!redisConfig.isAccessTokenExpired(jedis) && !forceRefresh) {
log.info("二次判断token有效,无需再次刷新");
return redisConfig.getAccessToken(jedis);
}
String url = String.format(WxMaService.GET_ACCESS_TOKEN_URL, this.getWxMaConfig().getAppid(),
this.getWxMaConfig().getSecret());
try {
HttpGet httpGet = new HttpGet(url);
if (this.getRequestHttpProxy() != null) {
RequestConfig config = RequestConfig.custom().setProxy(this.getRequestHttpProxy()).build();
httpGet.setConfig(config);
}
Date start = new Date();
try (CloseableHttpResponse response = getRequestHttpClient().execute(httpGet)) {
Date end = new Date();
String resultContent = new BasicResponseHandler().handleResponse(response);
WxError error = WxError.fromJson(resultContent, WxType.MiniApp);
if (error.getErrorCode() != 0) {
throw new WxErrorException(error);
}
WxAccessToken accessToken = WxAccessToken.fromJson(resultContent);
redisConfig.updateAccessToken(jedis, accessToken.getAccessToken(), accessToken.getExpiresIn());
return accessToken.getAccessToken();
} finally {
httpGet.releaseConnection();
}
} catch (IOException e) {
throw new RuntimeException(e);
}
} finally {
lock.unlock(jedis);
}
} finally {
jedis.close();
}
}
// 类文件 - cn.binarywang.wx.miniapp.config.impl.WxMaRedisConfigImpl$DistributedLock
/**
* 基于redis的分布式锁.
* 处理3:通过已有jedis连接获取和释放分布式锁,见lock()/unlock()
*/
private class DistributedLock implements GuoquanRedisLock {
private JedisLock lock;
private DistributedLock(String key) {
this.lock = new JedisLock(getRedisKey(key));
}
@Override
public void lock(Jedis jedis) {
try {
if (!lock.acquire(jedis)) {
throw new RuntimeException("acquire timeouted");
}
}catch (InterruptedException e){
throw new RuntimeException("lock failed", e);
}
}
@Override
public void unlock(Jedis jedis) {
lock.release(jedis);
}
}
在上面的代码中,主要改变如下,
- 处理1:获取分布式锁的当前线程,后续都将使用当前jedis连接完成后续操作。
- 处理2:二次判断token是否有效,避免循环刷新token。
- 处理3:通过已有jedis连接获取和释放分布式锁,见lock()/unlock()。
应用通过如上代码上线后,acquire timeouted的问题没有再出现,问题得到解决。
4. 发生的版本和后续WxJava优化
上面的问题存在WxJava的多个版本,包括v3.6.0到v3.8.0的版本。
直到v3.9.0及后续版本,可以看到相关问题的陆续修复,如下是两个相关的代码提交,
- 版本v3.9.0:优化小程序获取token逻辑,减少刷新请求次数,修复同上述处理2,
if (!this.getWxMaConfig().isAccessTokenExpired() && !forceRefresh) {
return this.getWxMaConfig().getAccessToken();
}
- 版本v4.2.0:标记JedisDistributedLock组件标记为Deprecated,不推荐使用来获取分布式锁。
在locks同一目录下有另外一个RedisTemplateSimpleDistributedLock的实现供配置使用,其在版本v3.9.0已经支持,需要进行如下配置,
# 存储配置redis(可选)
wx.mp.config-storage.type = redistemplate # 配置类型: Memory(默认), Jedis, RedisTemplate
更多配置请参考README文件。
5. 思考
有些问题一直不出现,不代表着不存在,在高并发情况下锁、线程池、连接池等资源竞争问题都将无限放大,可靠的软件产品需要经历一个持续不断打磨的历练过程。



