kubeadm join xxx:6443 --token xxx.xxx \
> --discovery-token-ca-cert-hash sha256:xxxx
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
根据日志输出,可知当前节点已加入集群,通过kubectl get nodes命令可以正常看到节点的状态为ready,但是通过kubectl get pods -A命令查看pods状态时,看到如下的CrashLoopBackOff的异常状态,
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system kube-flannel-ds-j69g6 0/1 CrashLoopBackOff 3 18m
通过kubectl logs命令查询pod日志可以看到报pod cidr not assigned的异常信息,
$ kubectl logs kube-flannel-ds-j69g6 -n kube-system
I0218 06:23:21.796296 1 main.go:518] Determining IP address of default interface
I0218 06:23:21.796512 1 main.go:531] Using interface with name eth0 and address 10.250.41.77
I0218 06:23:21.796525 1 main.go:548] Defaulting external address to interface address (10.250.41.77)
W0218 06:23:21.796537 1 client_config.go:517] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
I0218 06:23:21.906396 1 kube.go:119] Waiting 10m0s for node controller to sync
I0218 06:23:21.906791 1 kube.go:306] Starting kube subnet manager
I0218 06:23:22.906882 1 kube.go:126] Node controller sync successful
I0218 06:23:22.906912 1 main.go:246] Created subnet manager: Kubernetes Subnet Manager - worker-0001
I0218 06:23:22.906918 1 main.go:249] Installing signal handlers
I0218 06:23:22.906963 1 main.go:390] Found network config - Backend type: vxlan
I0218 06:23:22.907016 1 vxlan.go:121] VXLAN config: VNI=1 Port=0 GBP=false Learning=false DirectRouting=false
E0218 06:23:22.907246 1 main.go:291] Error registering network: failed to acquire lease: node "worker-0001" pod cidr not assigned
I0218 06:23:22.907272 1 main.go:370] Stopping shutdownHandler...
注:若在/var/log/syslog的日志中看到如下kubelet服务启动失败信息,可以先不用担心,在k8s master节点初始化之前,出现如下信息是正常的,kubelet会定时尝试连接k8s api server,直到成功。
kubelet[18544]: #011/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/go.opencensus.io/stats/view/worker.go:32 +0x57
systemd[1]: kubelet.service: Main process exited, code=exited, status=255/EXCEPTION
systemd[1]: kubelet.service: Failed with result 'exit-code'.
# kube-adm-images.sh
# 如下镜像列表和版本,请运行kubeadm config images list命令获取
#
images=(
kube-apiserver:v1.20.2
kube-controller-manager:v1.20.2
kube-scheduler:v1.20.2
kube-proxy:v1.20.2
pause:3.2
etcd:3.4.13-0
coredns:1.7.0
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
done
如下为本地拉取的镜像列表,
# 获取k8s集群控制平面所需的镜像
$ kubeadm config images list
19385 version.go:101] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get "https://storage.googleapis.com/kubernetes-release/release/stable-1.txt": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
19385 version.go:102] falling back to the local client version: v1.20.0
k8s.gcr.io/kube-apiserver:v1.20.0
k8s.gcr.io/kube-controller-manager:v1.20.0
k8s.gcr.io/kube-scheduler:v1.20.0
k8s.gcr.io/kube-proxy:v1.20.0
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns:1.7.0
# 查看本地镜像
$ docker images list
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-proxy v1.20.0 10cc881966cf 8 weeks ago 118MB
k8s.gcr.io/kube-controller-manager v1.20.0 b9fa1895dcaa 8 weeks ago 116MB
k8s.gcr.io/kube-scheduler v1.20.0 3138b6e3d471 8 weeks ago 46.4MB
k8s.gcr.io/kube-apiserver v1.20.0 ca9843d3b545 8 weeks ago 122MB
k8s.gcr.io/etcd 3.4.13-0 0369cf4303ff 5 months ago 253MB
k8s.gcr.io/coredns 1.7.0 bfe3a36ebd25 7 months ago 45.2MB
k8s.gcr.io/pause 3.2 80d28bedfe5d 11 months ago 683kB
# 主机节点网段:10.0.2.0/8
# k8s service网段:10.1.0.0/16
# k8s pod网段:10.244.0.0/16
# 启动k8s集群
$ sudo kubeadm init \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.20.2 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16
# 如下为完整运行日志
$ sudo kubeadm init \
> --image-repository registry.aliyuncs.com/google_containers \
> --kubernetes-version v1.20.2 \
> --service-cidr=10.1.0.0/16 \
> --pod-network-cidr=10.244.0.0/16
[init] Using Kubernetes version: v1.20.2
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 20.10.3. Latest validated version: 19.03
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local michaelk8s-virtualbox] and IPs [10.1.0.1 10.0.2.15]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost michaelk8s-virtualbox] and IPs [10.0.2.15 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost michaelk8s-virtualbox] and IPs [10.0.2.15 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 15.002558 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.20" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node michaelk8s-virtualbox as control-plane by adding the labels "node-role.kubernetes.io/master=''" and "node-role.kubernetes.io/control-plane='' (deprecated)"
[mark-control-plane] Marking the node michaelk8s-virtualbox as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: xxx.xxxx
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.0.2.15:6443 --token xxx.xxx --discovery-token-ca-cert-hash sha256:xxxx
# 下载k8s-deployment-nginx.yml文件,启动nginx
# 文件地址:https://gitee.com/pphh/blog/blob/master/210215_k8s_deployment/k8s-deployment-nginx.yml
$ kubectl apply -f k8s-deployment-nginx.yml
# 下载k8s-deployment-nginx-svc.yml文件,启动nginx服务
# 文件地址:https://gitee.com/pphh/blog/blob/master/210215_k8s_deployment/k8s-deployment-nginx-svc.yml
$ kubectl apply -f k8s-deployment-nginx-svc.yml
# 查看nginx状态
$ kubectl get pods -a
$ 查看服务运行情况
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.1.0.1 <none> 443/TCP 70m
nginx-service NodePort 10.1.8.186 <none> 8000:32000/TCP 8s
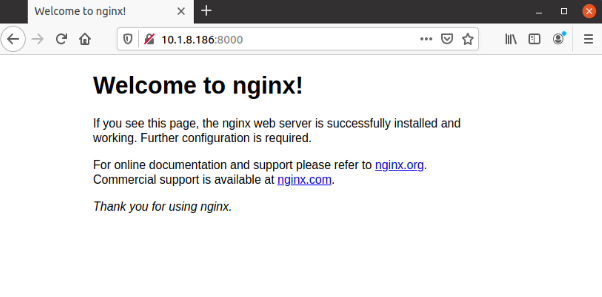
打开浏览器访问如下地址,
http://10.1.8.186:8000/
可以看到welcome to nginx的欢迎信息,
8. 安装过程中遇到的一些问题
8.1 无法查看docker镜像列表
执行docker images命令时,告知permission denied的异常,
$ docker images
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.24/images/json: dial unix /var/run/docker.sock: connect: permission denied
解决方案:切换到root账号下执行docker images命令即可。
8.2 拉取docker镜像问题
本文安装的k8s集群所用到的镜像如下,
$ sudo su -
root@michaelk8s-VirtualBox:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest f6d0b4767a6c 3 weeks ago 133MB
k8s.gcr.io/kube-proxy v1.20.0 10cc881966cf 8 weeks ago 118MB
k8s.gcr.io/kube-scheduler v1.20.0 3138b6e3d471 8 weeks ago 46.4MB
k8s.gcr.io/kube-apiserver v1.20.0 ca9843d3b545 8 weeks ago 122MB
k8s.gcr.io/kube-controller-manager v1.20.0 b9fa1895dcaa 8 weeks ago 116MB
quay.io/coreos/flannel v0.13.0 e708f4bb69e3 3 months ago 57.2MB
k8s.gcr.io/etcd 3.4.13-0 0369cf4303ff 5 months ago 253MB
k8s.gcr.io/coredns 1.7.0 bfe3a36ebd25 7 months ago 45.2MB
k8s.gcr.io/pause 3.2 80d28bedfe5d 11 months ago 683kB
nginx latest f6d0b4767a6c 3 weeks ago 133MB
# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system kube-flannel-ds-2ntmg 0/1 Init:ErrImagePull 0 4m51s
8.4 k8s集群初始化时报yaml配置文件已经存在
在主机上第二次运行kubeadm init命令时,会告知yaml配置文件已经存在的错误信息。
$ kubeadm init
[init] Using Kubernetes version: v1.20.2
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 20.10.3. Latest validated version: 19.03
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Swap]: running with swap on is not supported. Please disable swap
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
解决方案:运行kubeadm reset重置本地配置,然后再次执行kubeadm init命令。
kubeadm启动k8s集群还有其它的报错信息,比如,
[ERROR Swap]: running with swap on is not supported. Please disable swap.
5644 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
5644 kubelet.go:2163] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
在安装Flannel插件之前,这个是正常报错信息,安装之后该报错信息会消失。
8.6 运行kubectl命令报连接server localhost:8080被拒绝
异常信息如下,
$ kubectl describe pod
The connection to the server localhost:8080 was refused - did you specify the right host or port?